Configuration
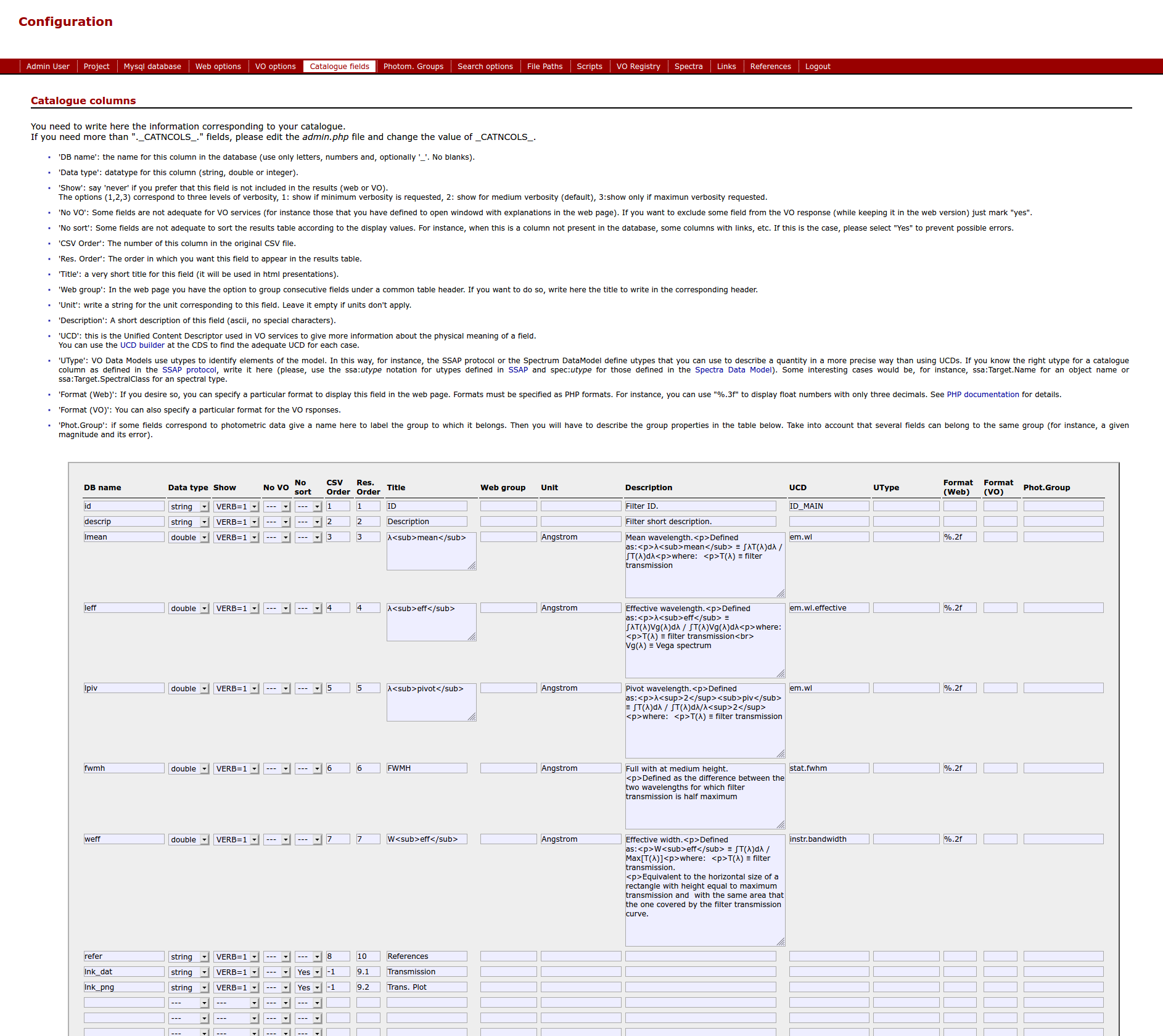
Catalogue fieldsThis one is probably the most important section of the configuration. And, given that you must write a lot of information, it can be the most confusing one. So we will try to explain the meaning of everything. The main idea is that your catalogue can be seen as a series of rows (one for each observation) and columns (a column for each property of that observation). We want that information stored in a database table with the same structure: rows and columns. And you probably have the information in a CSV file with the information separated by commas (meaning different columns). Here we ask you several things about the columns. In order to explain this more clearly let's look at the example included with the distribution. The structure of the data is:
and you have it as a CSV file like:
The idea is that there are 8 columns with different meanings. We want to know the meaning of each column (and some extra information). Now let's go to the configuration form:
(Click in the image for a larger version. It will be opened in a different window) Here you must fill as many rows as columns you have in your CSV file. That is, you have to give information about the 8 properties in your catalogue. You can also add columns in this configuration that are not part of your CSV or the database table. In this case we have included two columns (lnk_dat, lnk_png) as placeholders to show links to datafiles. These columns will be further configured later, in the Links section.
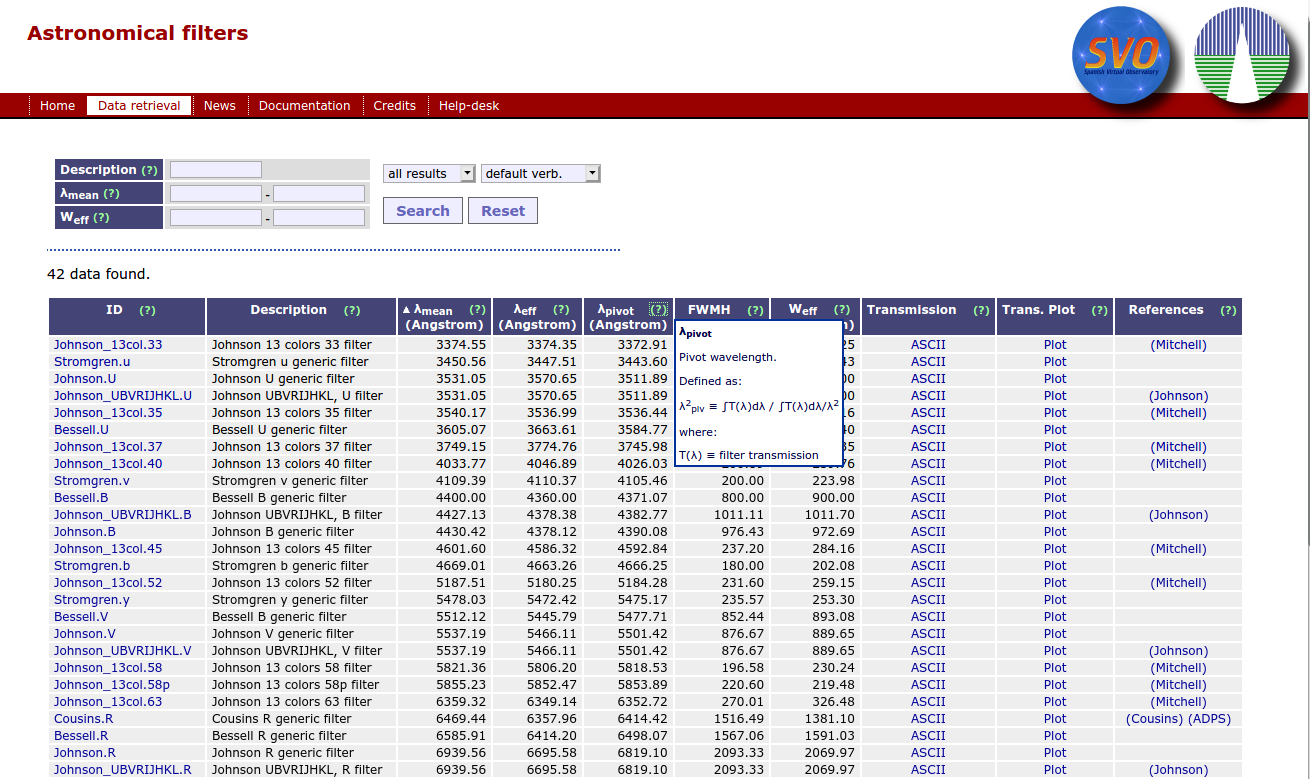
Here you can see the effect of some of these configuration options (but for understanding the three last columns you have to go to the Links and References sections).
|